Crawlers, ou rastreadores, coletam e processam informações de páginas da internet. Eles são a “base” de mecanismos de busca clássicos e de plataformas de IA generativa, como o ChatGPT ou Claude.
O detalhe é que os crawlers de IA são ligeiramente diferentes dos rastreadores usados para mecanismos de busca padrão.
As principais diferenças são:
Processamento de JavaScript, hoje uma das principais limitações dos crawlers de IA (exceto os do Google e da Apple);
Localização dos user agents, que são os identificadores usados para rastrear os sites;
Preferência por certos tipos de arquivo, que varia de acordo com cada LLM;
Eficiência de rastreamento, que tende a ser pior nos crawlers de IA.
Os dados são de um estudo publicado pela Vercel no fim do ano passado. A pesquisa também apontou uma correlação entre tráfego orgânico e rastreamento de páginas.
Veja abaixo os principais achados e entenda o que eles significam para você (e para a sua marca).
O que é um rastreador?
Antes de entender os detalhes dos crawlers de IA, vale entender o que são os rastreadores. Basicamente, são programas que coletam conteúdo de páginas da internet de forma automatizada.
O funcionamento básico de um crawler é:
Acessar URLs;
Ler o HTML carregado logo após a requisição, sem a execução completa de arquivos JS – ou seja, uma versão da página bem diferente do que os humanos acessam;
Descobrir novas URLs por meio dos links internos dessa página e dos sitemaps do site.
Esse processo ocorre de forma contínua e se estende por literalmente bilhões de URLs. Os dados coletados podem ser usados de várias formas, como exibir novas páginas no Google ou oferecer respostas atualizadas no ChatGPT.
Os crawlers se identificam com user agents específicos, permitindo que donos de sites indiquem quais seções podem ser acessadas por meio do arquivo robots.txt.
Os crawlers de IA
Crawlers de mecanismos de busca, como o Googlebot, e usados por LLMs, como Claude, Perplexity e ChatGPT, são muito parecidos com os crawlers “gerais”.
Para entender as diferenças para os bots usados por mecanismos de busca, a Vercel analisou a forma como foi rastreada por diversos user agents de IA. Eles traçaram um comparativo entre Googlebot, GPTBot, Claude, AppleBot e PerplexityBot.
O Copilot, da Microsoft, foi excluído da pesquisa porque usa múltiplos user agents.
Frequência de rastreamento
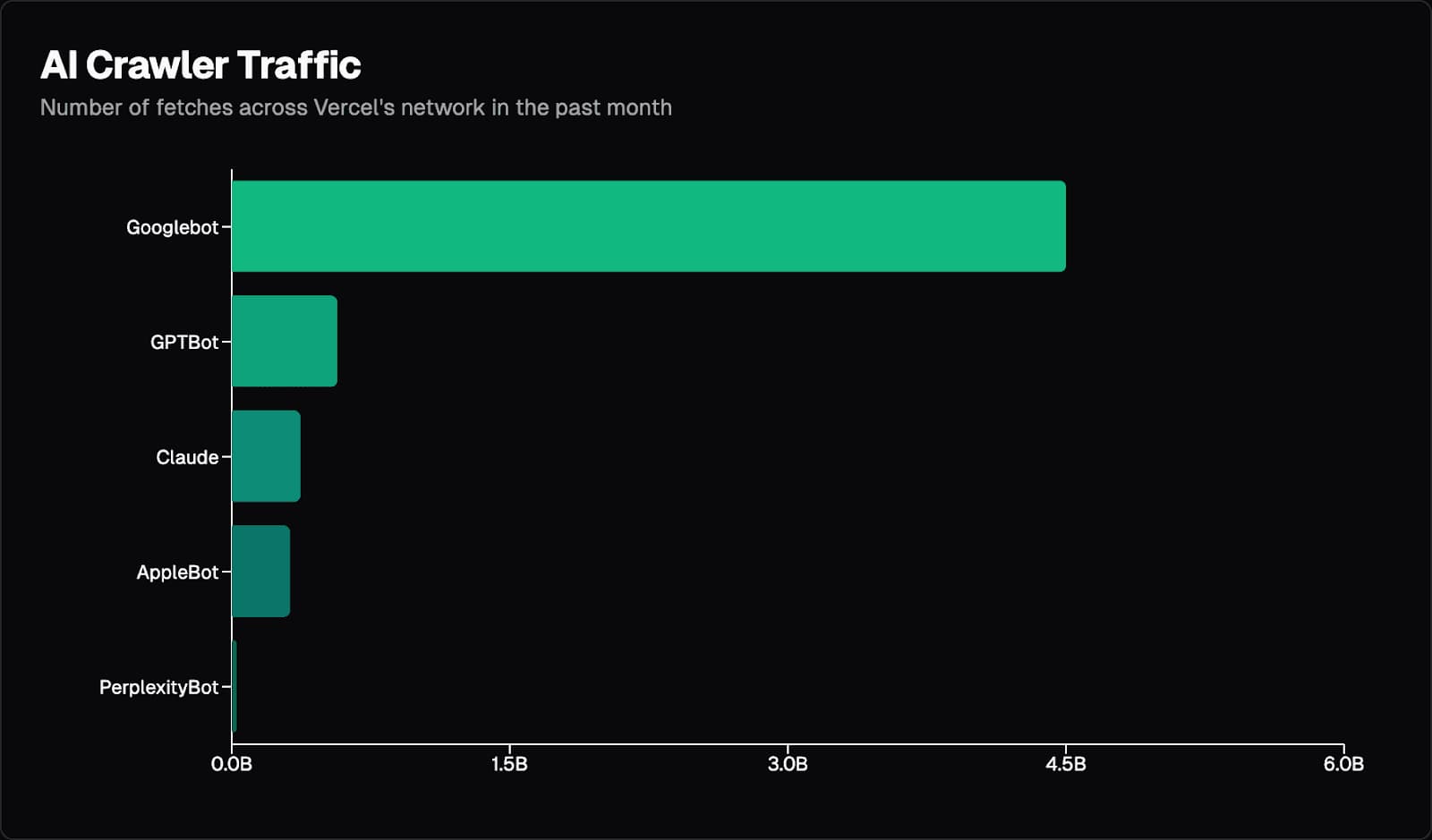
Os crawlers de IA fizeram bilhões de requisições às páginas analisadas, com destaque para o Googlebot, disparadamente o mais ativo.
Em novembro de 2024, os números foram:
Googlebot: 4.5 bilhões de requisições (entre produtos Gemini e Pesquisa);
GPTBot: 569 milhões de requisições;
Claude: 370 milhões de requisições;
AppleBot: 314 milhões de requisições;
PerplexityBot: 24.4 milhões de requisições.
Distribuição geográfica dos crawlers
Todos os crawlers de IA acessam as páginas a partir dos Estados Unidos. O ChatGPT sempre de Iowa ou Arizona, e o Claude sempre de Ohio.
Rastreadores de mecanismos de busca tradicionais costumam ficar espalhados. O Googlebot tem IPs em sete estados. E, caso detecte um bloqueio de IP dos EUA, pode tentar acessar a URL através de outros países.
Renderização de JavaScript
Crawlers de IA ainda não sabem renderizar JavaScript. Logo, se os conteúdos do seu site dependem de códigos JS para renderização, eles estão efetivamente “invisíveis” para as principais LLMs do mercado.
A Vercel descobriu que apenas Google e Apple conseguem renderizar JavaScript, e usam tecnologias muito parecidas para isso.
Os principais destaques foram:
O Gemini usa a infraestrutura robusta do Googlebot para renderizar totalmente as páginas;
O AppleBot percorre um caminho similar ao Googlebot para renderizar páginas. Ele pode processar JS, CSS, Ajax e demais recursos;
ChatGPT e Claude conseguem reconhecer arquivos JS, mas não executá-los. Logo, não renderizam.
De um ponto de vista de SEO e branding, se o seu conteúdo é renderiza do do lado do cliente, você pode estar perdendo espaço nas LLMs. No futuro, possivelmente todas conseguirão processar JS corretamente, mas até lá, você precisa se adaptar ao cenário atual.
Tipos de conteúdos priorizados no rastreamento
Cada IA tem suas preferências próprias sobre os conteúdos que são rastreados.
ChatGPT prioriza arquivos HTML;
Claude foca mais em imagens;
Googlebot distribui recursos entre HTML, dados JSON, texto puro e JavaScript.
Segundo a Vercel, a preferência por certos tipos de arquivo pode indicar interesses específicos no treinamento de novos modelos de LLM. O Googlebot não tem essa preocupação, pois a infraestrutura do rastreador foi montada para outra finalidade, que é a indexação de páginas da web.
Crawlers de IA ainda são ineficientes
Os rastreadores das LLMs gastam muito tempo e recursos em páginas que não existem.
Em números:
34.82% das requisições do ChatGPT são para páginas 404. Outros 14.36% são seguindo redirects;
34.16% das requisições do Claude são para páginas 404;
Apenas 8.22% das requisições do Googlebot são para páginas 404 e 1.49% para redirects.
Páginas com mais tráfego são mais visitadas
Um detalhe interessante sobre a pesquisa é que existe uma correlação entre rastreamento e tráfego orgânico.
No entanto, este pode ser um comportamento temporário. Dacordo com a pesquisa, as plataformas de IA ainda estão aprendendo quais tipos de URLs devem ser priorizadas.
Escolher páginas populares pode ser apenas um ponto de partida para as novas IAs, o que não é necessário para rastreadores já consolidados, como o Googlebot.
Futuramente o cenário pode ser outro.
O impacto do rastreamento feito pelas IAs
Entender o funcionamento dos crawlers de IA muda como interagimos com as plataformas.
Para donos de site, é o momento de pensar em questões técnicas importantes, como:
Usar renderização do lado do servidor (SSR) para conteúdos com potencial para SEO. Incluem-se aqui posts de blog, informações sobre produtos, documentações, meta tags, estruturas de navegação e outros elementos semelhantes. Se esse tipo de informação depender de JS para carregar, a IA simplesmente não os enxergará;
Renderização do lado do cliente (CSR) ainda deve ser usada para funções não-críticas, como elementos interativos, widgets, feeds de rede social, além de páginas dinâmicas e aplicações web;
Gerenciar corretamente as URLs do seu site é mais importante do que nunca. Os crawlers de IA ainda são ineficientes, então quanto mais você facilitar o trabalho deles, melhor;
Mantenha as boas práticas de SEO para gerenciar URLs. Corrija erros 404, mantenha seus sitemaps atualizados e use estruturas de links consistentes nas suas páginas;
Usar arquivos robots.txt para controlar o que os rastreadores de LLM podem acessar. Verifique as documentações das plataformas de IA para encontrar os seus user agents;
Para quem pesquisa na IA, é importante lembrar das limitações da tecnologia. Quase ⅓ das requisições são feitas a páginas 404, então você não pode confiar cegamente no que a LLM entrega. Sempre que possível, acesse o site que é mencionado como fonte e veja quais informações estão lá.
__
O futuro do SEO na era da IA
É fato que a otimização para mecanismos de busca está mudando rápido. Mas, quanto mais analisamos, mais vemos semelhanças entre o “SEO tradicional” e o “SEO para IA”.
As estruturas são parecidas e as boas práticas de visibilidade também seguem as mesmas, apesar das diferenças nos crawlers de IA para os crawlers de mecanismos de busca tradicionais.
Se você sente que está ficando para trás nesse cenário de transformações, entre em contato com a SEO Happy Hour. Estamos acompanhando cada atualização de perto e podemos te ajudar a fechar novos negócios, não importa onde os seus clientes procuram por informações.
Elyson Gums é redator na SEO Happy Hour. Trabalha com redação e produção de conteúdo para projetos de SEO e inbound marketing desde 2014, em segmentos B2C e B2B. É bacharel em Jornalismo (Univali/SC) e mestre em Comunicação Social (UFPR).

Comentários