No fim de junho, o Google anunciou um novo algoritmo, chamado Muvera. Ele permite que o buscador obtenha respostas para perguntas complexas com mais rapidez e precisão.
Trata-se de um sistema de Recuperação de Informação. Em termos técnicos, ele permite que a recuperação multivetorial seja tão rápida quanto a recuperação de vetores únicos.
Falando em bom português: o Google agora interpreta pesquisas de forma diferente, entregando resultados melhores, de forma quase imediata, sem gastar recursos adicionais.
Veja a seguir como ele funciona e como interfere nas rotinas de SEO.
O que são embeddings e vetores?
O Muvera é uma forma diferente de lidar com os vetores e os embeddings no processo de acessar a informação que está nos índices do Google.
Embeddings e vetores são representações numéricas do significado das palavras. Esses elementos são fundamentais para que IAs consigam entender o significado das palavras e frases.
Por meio deles, mecanismos de busca podem funcionar a partir de semântica. Ou seja, interpretando o significado de cada palavra e frase. Uma patente do ChatGPT descreve o conceito assim:
A busca semântica vai além da busca por palavras-chave (que depende da ocorrência de termos específicos no texto da consulta) para encontrar dados contextualmente relevantes com base na similaridade conceitual da entrada. Como resultado, buscas semânticas em uma base de conhecimento podem fornecer mais contexto para os modelos. A busca semântica pode utilizar um banco de dados vetorial, armazenando trechos de texto (derivados de alguns documentos) e seus vetores (representações matemáticas do texto). Ao consultar esse banco vetorial, a entrada da busca (em forma de vetor) é comparada com todos os vetores armazenados, e os trechos de texto mais semelhantes são retornados.
Mecanismos como o ChatGPT e Perplexity funcionam inteiramente com base em semântica. Buscadores tradicionais, como o Google, combinam as abordagens semânticas e léxicas (com palavras-chave).
O que são embeddings?
Um embedding é uma representação numérica de significado. É uma forma de converter conceitos abstratos, como uma pergunta, uma frase ou uma imagem, em uma sequência numérica entendível por máquinas.
Por exemplo, quando você pergunta “qual é a altura do Monte Everest?”, o sistema não procura pela frase exata em uma URL. Ele converte essa pergunta em vetores (já já explicamos o que são) para entender o visitante quer saber.
O sistema pode relacionar essa pergunta a outros conceitos, como “altura”, “montanhas” ou “geografia” e transformar essas associações em sequências numéricas também.
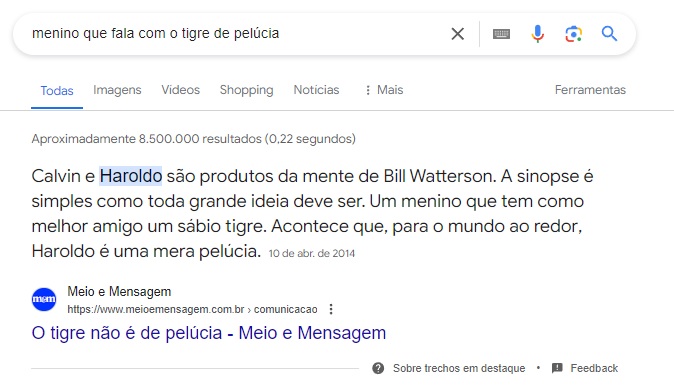
Um dos meus exemplos preferidos é a pesquisa sobre “menino que conversa com o tigre de pelúcia”. Se você digita isso no Google, aparecem o Calvin e o Haroldo, mesmo que nenhuma página tenha a frase pesquisada no texto.
Buscadores entendem que você quer descobrir quem são aqueles personagens. Aí, ele procura as entidades relacionadas e responde à questão. Tem vários exemplos assim, como “gato que adora lasanha e odeia segundas-feiras” ou “menino que mora num barril”.
O que é um vetor?
O vetor é a forma matemática de um embedding. Ou seja, são praticamente sinônimos, já que os vetores ficam incorporados em um “espaço” onde podem estar próximos ou mais afastados.
Ficou meio abstrato, mas podemos imaginar da seguinte forma:
Imagine que o vetor é uma flecha;
Esta flecha está apontando para uma direção aleatória no espaço;
A direção diz qual é o sentido de uma expressão;
O tamanho da flecha fala com qual força aquele sentido está expresso.
Fica mais fácil quando a gente imagina os vetores em relação entre si.
Imagine um vetor chamado Shakespeare, que contém todas as informações sobre a figura: é um escritor, um dos maiores nomes da Literatura, escreveu tragédias, é autor de peças icônicas como Romeu e Julieta e Hamlet.
Cada uma dessas características – escritor, Literatura, tragédia, Romeu e Julieta, Hamlet – é um vetor.
As “flechas” entre esses vetores serão curtas, pois os assuntos conversam entre si e compartilham significados.
E se a gente considerar os vetores Shakespeare e Donald Trump? Eles terão relação mínima, estarão distantes no espaço, com poucas ou nenhuma conexão.
Sempre que você faz uma pergunta para o ChatGPT ou o Google, eles fazem esse processo de encontrar similaridades entre os significados.
No processo de busca, quando a pesquisa e a URL compartilham vetores similares, significa que aquela URL provavelmente é uma boa resposta, mesmo se as palavras forem completamente diferentes.
Você pode imaginar cada conteúdo, frase ou parágrafo sendo transformada em um ou mais vetores. Quanto mais vetores, mais complexo é o processo de recuperar a informação – e é aí que o Muvera ajuda.
O que é recuperação de vetores únicos?
Neste método de recuperação de informação, o sistema gera um vetor por pesquisa e um vetor por documento. Em seguida, compara ambos para entregar a resposta. Os conteúdos que tiverem vetores mais parecidos serão exibidos como resposta.
É um processo rápido e que funciona bem para perguntas simples, como “qual é a altura do Monte Everest” ou “qual é a cor do céu”. Mas, quando a resposta exige múltiplos conceitos, ou a intenção de busca precisa de algum contexto adicional, os resultados não são tão precisos.
O que é recuperação multi-vetorial?
No método de recuperação multi-vetorial, vários vetores são criados para cada pesquisa e para cada URL. Uma única frase pode ter dezenas de vetores, dependendo de quantas palavras ela contém.
Imagine que alguém pesquise “quais são as montanhas mais altas do mundo?”. Essa pesquisa envolve muitas montanhas, a comparação entre elas, o processo de documentar a altura de cada uma, etc. Ou então “desde quando Shakespeare é considerado o maior nome da Literatura em língua inglesa?”.
Nesse tipo de pesquisa, usar um só vetor pode simplificar demais os conceitos, o que resulta em uma resposta não tão boa.
Qual problema o Muvera resolve?
Já se sabia que a multi-vetorização gera respostas melhores, mas não havia um jeito de colocar em prática. O processo é naturalmente mais demorado e mais caro do que a pesquisa com vetores únicos.
O Muvera usa uma técnica chamada Codificação Dimensional Fixa (FDE), que comprime vetores, mas preserva informação o suficiente para se aproximar de uma similaridade multi-vetorial.
É uma simplificação que torna a recuperação de múltiplos vetores muito mais rápida, comparada à recuperação de vetores únicos.
Esse funcionamento pode ser aplicado em vários sistemas, como a Pesquisa Orgânica, os recursos de IA do Google, sistemas de recomendação, como o YouTube, e processamento de linguagem natural (PLN).
Como o Muvera funciona?
O Muvera analisa como todos os vetores de uma pesquisa se relacionam entre si. Ele “agrupa” essa representação em um vetor único. Ou seja, o vetor passa a representar aquele todo, sem simplificar os seus significados.
Para isso, os vetores são agrupados em espaços imaginários. Para as pesquisas, o Muvera soma os vetores que estão em cada espaço. Para as URLs no índice, o algoritmo faz uma média dos vetores presentes em cada espaço. Na hora de exibir as respostas, compara os resultados.
Fica meio confuso de visualizar só com texto (na real, foi difícil até de escrever), então veja como funciona nos diagramas produzidos pelos pesquisadores do Google.
Este é o processo para pesquisas:
E aqui o que acontece na hora de interpretar uma resposta:
O Muvera torna o Google mais preciso na hora de responder perguntas complexas.
Isso tem diversas implicações para a área de SEO:
Gera respostas melhores para perguntas que envolvem múltiplos assuntos, como as que são feitas frequentemente em LLMs, como o ChatGPT;
Conteúdos que cobrem tópicos de forma aprofundada, estabelecendo múltiplas relações semânticas, podem se tornar mais importantes dentro das estratégias de SEO;
Palavras-chave podem perder importância, principalmente quando elas são o foco das otimizações de conteúdo.
É necessário otimizar conteúdos para o Muvera?
Não existe otimização de conteúdos para o Muvera. O algoritmo faz parte da infraestrutura de recuperação de informação do Google. Logo, é bem diferente dos core updates ou dos sinais de ranqueamento de páginas.
Dito isso, entender como a recuperação de informações funciona interfere nas estratégias de conteúdo e SEO.
Sabendo que o Google consegue gerar respostas com base em análises complexas de semântica, significa que você pode se alinhar a essa realidade.
As formas de fazer isso são:
Gerar riqueza semântica: cubra assuntos a partir de múltiplos ângulos, abordando todas as entidades que podem ser úteis, mesmo que envolva termos completamente diferentes. Por exemplo, falar de “tirar fotos em público” também envolve falar de “iluminação”, “atenção à posição do sol”, “melhores horários para fotos” e “fotografia outdoor”;
Estruture seu texto: organize seu texto de forma lógica, com headings claros e fáceis de acompanhar;
Atente-se para a intenção de busca: entenda o que as pessoas querem saber e entregue exatamente essa informação. Depois, apresente outros tópicos que se relacionam e ajudam a atender a essa intenção de busca.
Retomando o exemplo que usamos ao longo desse post, imagine um texto sobre “qual é a altura do Monte Everest?”.
Você não precisa “otimizar” o texto para essa frase. Em vez disso, concentre-se em responder diretamente:
Qual é a altura do Monte Everest;
Qual é a diferença para os outros picos mais altos do mundo;
Como essa altura é medida;
Quais países estão envolvidos na medição;
Se o número é absoluto ou se há algum debate;
Quais tecnologias são usadas para medir montanhas;
Se tem diferença de altura medindo do nível do mar e da base da montanha;
Se algum evento geológico, como um terremoto, mudou a altura da montanha;
Qual é a diferença para outras montanhas da região;
Quais os impactos da altura, como a dificuldade de oxigênio ou tempo que leva para escalar.
Esse tipo de abordagem, mais detalhada e complexa, pode gerar melhores resultados em mecanismos que usam busca semântica.
__
Entre em contato com a SEO Happy Hour e obtenha o apoio de especialistas para conduzir uma estratégia de SEO que continua relevante mesmo com os avanços das IAs e mudanças nos buscadores.
Elyson Gums é redator na SEO Happy Hour. Trabalha com redação e produção de conteúdo para projetos de SEO e inbound marketing desde 2014, em segmentos B2C e B2B. É bacharel em Jornalismo (Univali/SC) e mestre em Comunicação Social (UFPR).

Comentários