O Departamento de Justiça dos EUA revelou alguns documentos que expõem os “bastidores” do Google. São relatórios e transcrições de testemunhos que trazem várias informações úteis e interessantes para quem faz SEO.
Entre os tópicos abordados estão os sinais de ranqueamento, sistemas internos, a função dos avaliadores humanos, o papel das LLMs (modelos de linguagem de grande porte) na classificação de páginas, entre outras questões.
O relatório revelou até o interesse da OpenAI em usar o Google para alimentar a pesquisa do ChatGPT! 🤯
Veja abaixo a tradução das principais informações, a partir de análise feita pelo portal Search Engine World.
Os sinais e sistemas do Google
A estrutura do Google se baseia em um conjunto de sinais e sistemas que permitem entender quais páginas são as mais relevantes para cada pesquisa. Há centenas deles, alguns gerados por LLMs, outros criados “manualmente”.
Internamente, a nomenclatura usada é:
Documentos: as versões salvas das páginas;
Sinais: são os critérios para avaliar as páginas, que alimentam algoritmos como o PageRank.
Existem tipos diferentes de sinais:
“Crus”, que são sinais individuais;
“Sinais de topo”, uma combinação de múltiplos sinais tradicionais.
Eles podem ser gerados de forma preditiva, através de LLM, ou com base em dados reais de navegação, chamados de sinais tradicionais.
Exemplos de sinais e sistemas do Google
Durante o processo, os engenheiros discutiram alguns sistemas específicos. Conhecemos muito pouco sobre alguns deles, pois não são documentados publicamente.
São eles:
Q Star: usado para determinar a qualidade de uma página;
Navboost: mede os cliques em páginas, segmentando por local e tipo de dispositivo;
RankEmbed: sinal treinado com LLMs;
PageRank: algoritmo clássico do Google para avaliar relevância a partir de links;
Twiddlers: usados para “reranquear” páginas.
Os sinais são “combinados” em uma pontuação única, que define a posição orgânica do site.
Os “sinais manuais” do Google
Os documentos mencionam termos como “hand crafted signals”. Em tradução, seria algo como “sinais manuais”, o que é um termo pouco falado no universo de SEO.
São sinais que podem ser manualmente ajustados e analisados por engenheiros. Se houver necessidade, o Google pode selecionar dados aleatoriamente para fazer análises regressivas detalhadas.
Até mesmo os dados gerados por sistemas de IA, como o BERT, podem ser “desconstruídos” até ficarem “muito próximos” de sinais tradicionais. Combinando ambas as abordagens, o desempenho dos algoritmos melhora.
Por que o Google evita depender de machine learning?
Segundo o Google, seria um erro automatizar o processo de geração de dados para ranqueamento. Por meio dos “sinais manuais” e tradicionais, a equipe de engenharia tem mais liberdade para entender e melhorar os algoritmos.
Isto seria o oposto da Microsoft, que se baseia em deep learning. O trecho do processo diz:
A razão pela qual a maioria dos sinais é manual é porque se algo quebra, o Google sabe como consertar. O Google quer que seus sinais sejam completamente transparentes para que possam testar e melhorar.
A Microsoft constrói sistemas complexos usando técnicas de machine learning para otimizar funções. Então é difícil consertar algo, por exemplo, saber onde ir e como resolver uma função. Deep learning piorou tudo.
Essa é uma vantagem do Google sobre o Bing e outros buscadores. O Google enfrentou muitos desafios e foi capaz de responder.
Nota: os sinais devem ser “completamente transparentes” para a equipe de engenharia, não para o público geral.
O ABC do Google
Entre os sinais discutidos no processo, os que mais chamam a atenção são os sinais ABC, que descrevem elementos básicos do ranqueamento do Google.
A de Anchor (âncora) ou links para os quais uma página aponta;
B de Body (corpo), que são os termos do documento;
C de Clicks (cliques), o tempo que a pessoa permaneceu na página antes de voltar à SERP.
Juntos, esses sinais formam a “topicalidade”, que é uma pontuação do quanto uma página é relevante para determinada pesquisa. Esse algoritmo foi trabalhoso para montar e só foi concluído cerca de cinco anos atrás.
Como de costume, os sistemas não funcionam de forma isolada. Logo, além de topicalidade, qualidade da página, confiança, e outros critérios também são levados em conta na hora de escolher quais páginas aparecem.
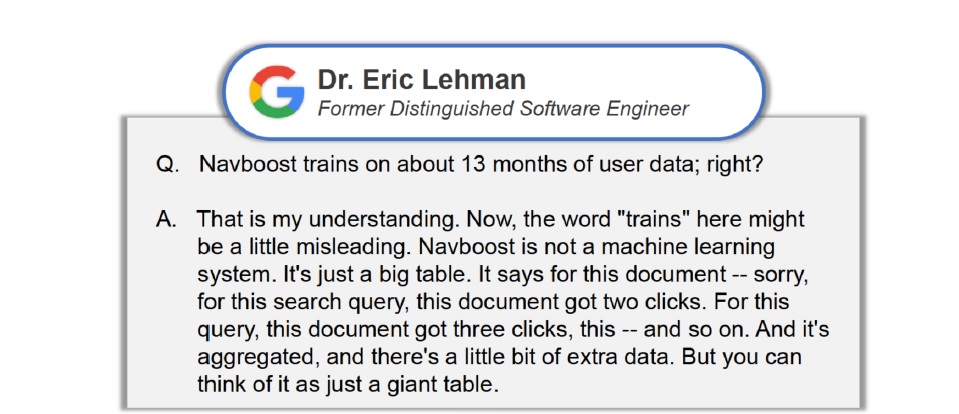
O Navboost “é uma tabela”
O Navboost foi descrito com um dos “sistemas mais poderosos” do Google, na última rodada de documentos do processo contra a big tech. O sistema é capaz de medir a interação das pessoas com as páginas e usa dados dos últimos 13 meses.
Eric Lehman, ex-funcionário da empresa, explicou que na verdade ele se trata de uma “grande tabela”:
A palavra “treinado” pode ser meio enganosa. O Navboost não é um sistema de aprendizado de máquina. É só uma grande tabela. Ele diz… Para essa pesquisa, esse documento teve dois cliques. Para essa, esse documento teve três cliques, e assim por diante. É agregado e tem um pouco mais de dados extras, mas você pode pensar nele como uma grande tabela.
Decomposição das buscas
A equipe interna tem uma ferramenta para “debugar” a pesquisa do Google e entender em detalhes como os algoritmos estão entendendo o que as pessoas digitam.
Veja a tradução:
Pandu (Nayak, engenheiro do Google) digitou “james allan umass” em uma tela de pesquisa do Google e ativou a interface de debug, mostrando:
[censurado] o processo de expansão e decomposição da pesquisa.
Por exemplo, “umass” sendo reescrito como Universidade de Massachusetts, James como um primeiro nome, Allan também podendo ser escrito como Allen, etc. [censurado] contendo uma tabela com uma lista de 10 links azuis e pontuação correspondente para cada sinal de topo, assim como um total final correspondente (“Final IR”).
Volume de uso do ChatGPT ainda não se compara ao Google
Apesar dos relatos de que “o Google está perdendo espaço”, a quantidade de acessos ainda não se compara. Na verdade, não está nem perto disso.
Segundo os documentos do processo, em dezembro de 2024:
O Google recebeu 8.3 bilhões de pesquisas por dia;
As AI Overviews apareceram 600 milhões de vezes por dia;
Perplexity estava fazendo 20 milhões de “mensagens”;
Os números do ChatGPT foram censurados, mas no gráfico, ele aparece com um número de mensagens ligeiramente maior que as AI Overviews no período.
Agora que a parte técnica já passou, uma curiosidade para quem chegou até aqui: a OpenAI procurou o Google para alimentar a busca do ChatGPT, quando este ainda era um protótipo.
O Google recusou a oferta de integrar a sua API à plataforma, como mostra o e-mail abaixo:
O contexto do processo contra o Google
Um detalhe importante: o Google não quis divulgar essas informações. Se dependesse da empresa, continuariam secretas. Elas só viram a luz do dia por causa do processo movido contra a big tech.
Os nomes são estranhos porque são os “códigos” do governo norte-americano para cada documento. Outro detalhe é que certos pontos foram censurados pelo Departamento de Justiça antes de serem disponibilizados ao público.
__
Para acompanhar todas as novidades do mercado de SEO, incluindo a cobertura completa do processo dos EUA contra o Google, siga a SHH no Linkedin e YouTube!
Elyson Gums é redator na SEO Happy Hour. Trabalha com redação e produção de conteúdo para projetos de SEO e inbound marketing desde 2014, em segmentos B2C e B2B. É bacharel em Jornalismo (Univali/SC) e mestre em Comunicação Social (UFPR).








Comentários