JavaScript mal implementado pode causar uma série de problemas no seu site, desde carregamento lento até conteúdo invisível para os mecanismos de busca.
Fica pior ainda para as plataformas de IA, como o ChatGPT e Perplexity, já que elas muitas vezes são incapazes de renderizar JS.
Neste post, você entenderá como JavaScript influencia o SEO, quais são os problemas mais comuns e as boas práticas recomendadas.
É um guia para que você entenda melhor o desempenho do seu site e consiga conversar com mais propriedade com os desenvolvedores da sua equipe.
Como e por que JavaScript afeta SEO?
O JavaScript pode dificultar a leitura e indexação de conteúdo por mecanismos de busca. Elementos interativos, como menus dinâmicos, filtros, carrosséis e pop-ups, são úteis para a experiência do usuário, mas nem sempre são renderizados corretamente pelos mecanismos de busca. Aí, ficam invisíveis.
Se os buscadores tiverem dificuldades para entender a página, podem não saber quando exibi-la, ou qual tipo de conteúdo realmente está ali, o que se traduz em menor visibilidade para os portais.
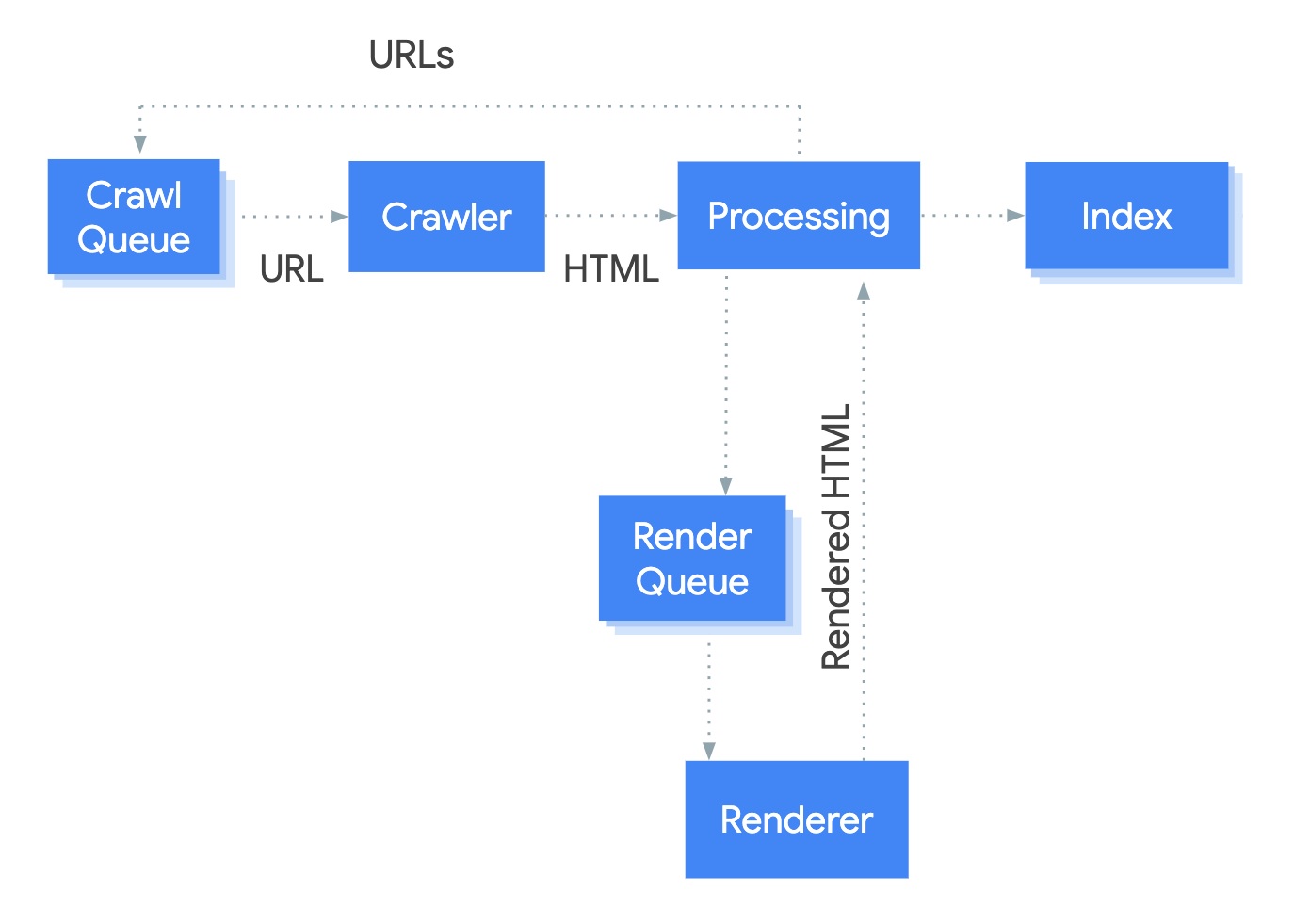
Para que uma página possa ser exibida, ocorrem três etapas, chamadas de rastreamento, renderização e indexação. O JavaScript é processado apenas durante a renderização.
O rastreador faz uma requisição para acessar a página. Aqui, ele lê o arquivo HTML daquela URL;
Quando o rastreador identifica algum código que requer processamento adicional, como o JS, essa URL é enviada para uma fila de renderização;
O JavaScript é renderizado e a página é processada. Apenas aqui o Google tem uma visão do que está “por trás” do JS na página.
E os rastreadores de IA?
Na IA, os processos são bem diferentes. Por enquanto, boa parte deles ainda não aprendeu a renderizar JavaScript. Ou seja, apenas fazem a requisição para acessar uma URL, consomem o HTML e param por aí. Elas também não armazenam um índice, da mesma forma que os buscadores tradicionais.
O Gemini consegue processar JS pois usa a infraestrutura do Googlebot, apresentada acima;
ChatGPT e Claude reconhecem arquivos JS, mas não podem executá-los;
AppleBot pode processar JS (inclusive Ajax).
O processo de renderização de sites
Renderização significa transformar o código-fonte de uma página (HTML, CSS e JS) em uma versão visual e funcional, com a qual as pessoas podem interagir.
Na renderização do lado do servidor (SSR), o conteúdo da página é acessível no HTML, porque o processo de renderização foi feito direto no servidor e não no navegador do visitante.
Já a renderização do lado do cliente (CSR) depende do navegador renderizar o HTML inicial para exibir o conteúdo da página.
Também existe uma “terceira alternativa” chamada renderização dinâmica, que exibe uma versão da página para requisições que não conseguem renderizar JS, e a versão “completa” para quem consegue.
Para SEO, a recomendação geral é usar SSR em páginas estáticas e CSR em páginas dinâmicas. Já a renderização dinâmica é chamada pelo Google de “solução provisória”.
Quais os impactos do JavaScript mal implementado em um site?
Quando o rastreamento ou a execução dos códigos não acontece como deveria, pode haver queda de performance e dificuldade para os buscadores entenderem as páginas, o que prejudica a visibilidade (e o tráfego) em mecanismos de busca.
As consequências podem ser:
Site não ser indexado;
Páginas não carregarem ou ficarem travadas para navegar;
Páginas indesejadas aparecendo no Google, como URLs dinâmicas;
Quedas de performance após migração ou redesign, geralmente por mudanças de plataforma.
A parte mais difícil de detectar estes impactos é que as causas podem ser diversas. Inclusive, às vezes a culpa nem é do JavaScript! As soluções podem envolver auditorias no código-fonte do site e análises em outros aspectos de SEO técnico.
Causas e soluções para os erros de JavaScript
Agora que já passamos pela parte teórica, vamos ao que interessa, a lista de problemas frequentes:
Google não consegue descobrir URLs;
Google não consegue rastrear determinados elementos da página;
Dependência de renderização do lado do cliente (CSR);
Rastreadores não podem acessar recursos para exibição das páginas;
Google não consegue renderizar a página corretamente;
Elementos de cabeçalho estão ausentes;
Páginas indesejadas geradas por JavaScript.
Cada item tem uma série de possíveis causas e soluções. Abaixo, vamos explorar as principais.
1. O Google não consegue descobrir URLs
Antes de rastrear qualquer página, o Googlebot precisa descobrir que ela existe.
JavaScript mal implementado pode impedir as duas primeiras ações. Já a terceira está fora do controle de donos de sites.
Como descobrir o problema: acesse o relatório de estatísticas de rastreamento no Google Search Console. Se houver quedas no número de solicitações, vale investigar os motivos.
Possível causa: URL inválida
Algumas stacks de JS usam # (fragmento) para carregar diferentes conteúdos na página. URLs fragmentadas são válidas para os visitantes, mas por padrão o Googlebot não as segue.
Solução: usar API history em vez de fragmentos nas URLs.
O Googlebot apenas segue links que estão marcados com o elemento HTML <a>. Links inseridos via JavaScript também devem aparecer como elementos HTML;
Solução: configurar sempre links como elementos HTML <a href>.
Possível causa: problemas de paginação
Certos tipos de paginação podem tornar links invisíveis para o Google, como aquelas que exigem alguma função JavaScript para exibir o conteúdo. Nesse caso, as próximas páginas ficariam “invisíveis” para o rastreador.
Solução: seguir as diretrizes para paginação do Google. É necessário seguir diversas regrinhas técnicas, que envolvem desde o estilo de paginação, links e canonização de páginas.
As principais bibliotecas JavaScript têm recursos para criação de sitemaps que são atualizados dinamicamente. Se houver algum erro, pode impactar na descoberta de páginas.
Solução: Revisar com frequência o seu sitemap, observando principalmente se está sendo atualizado corretamente.
Se houver links indesejados, que não devem ser indexados (como URLs de variantes de produtos ou de páginas internas), remova-os.
2. O Google não consegue rastrear alguns elementos da página
Ao renderizar as páginas, é possível que o Google “perca” alguns elementos, como textos, imagens ou links, caso eles dependam de JS para aparecer.
Ou seja, ele pode rastrear uma versão incompleta da página, ou não indexá-la por não compreender totalmente o seu conteúdo.
Como descobrir o problema: você pode usar a ferramenta de teste de URL em tempo real do Google Search Console para descobrir se a renderização está correta.
Os passos são:
Abra o GSC;
Inspecione as URLs principais do site (as que são de “template” para outras páginas, como a sua home, páginas de produto, página inicial do blog, página padrão de posts, etc.);
Pressione “ver a página rastreada”;
Clique em “captura de tela”;
Selecione “testar o URL publicado”.
Você verá uma aba com o código-fonte que o Google leu e outra aba com a versão renderizada da URL. Se perceber elementos faltando, investigue mais a fundo junto aos desenvolvedores da sua equipe.
A aba “mais informações” também oferece pistas do que pode estar acontecendo. Ela exibe, por exemplo, recursos que estão bloqueados ou não carregaram corretamente.
Possível causa: elementos bloqueando a renderização
Certos tipos de scripts podem bloquear a exibição completa do conteúdo na hora em que o Googlebot acessa a página. Podem ser abas, menus accordion, links em paginação ou links em menu com dropdown.
Solução: analise se os elementos que estão faltando são críticos para a experiência de página. Se sim, precisará implementá-los de outra forma.
Frequentemente eles são adicionados da mesma forma em todo o site, então será necessário fazer uma “limpa” geral no código com o apoio da equipe de desenvolvimento.
Possível causa: conteúdo carregado dinamicamente depois de interação do visitante
Os rastreadores não realizam nenhuma ação dentro das páginas. Ou seja, eles não clicam, rolam para baixo ou passam por cima de menus. Se um conteúdo depende dessas ações para aparecer, ele ficará invisível para os mecanismos de busca. E, como resultado, a página será rastreada de forma incompleta.
Solução: o conteúdo deve estar disponível no HTML do site antes de qualquer interação. Use a ferramenta de inspeção do navegador (CTRL+Shift+C) e analise o código-fonte. Se o conteúdo estiver lá antes do clique, está tudo certo.
3. Dependência de renderização do lado do cliente (CSR)
Em CSR, elementos importantes da página podem não estar disponíveis antes da renderização. Ou seja, estão ausentes do HTML do site. Isso dificulta o trabalho dos rastreadores.
A “hierarquia” dos elementos da página é:
Básicos: title, meta description, meta robots e canonical;
Importantes: links de navegação, paginação, H1 e outros headings;
Ideais: texto da página, links, imagens e textos alternativos.
Como descobrir o problema: inspecione o HTML das suas páginas e veja se o arquivo contém os elementos básicos. Se sim, e mesmo assim a página não é indexada, o problema pode ter a ver com a renderização.
O plugin View Rendered Source permite comparar facilmente o conteúdo renderizado com o conteúdo HTML original. É bem útil para resolver problemas desse tipo.
Possível causa: o tipo de renderização
Se o seu site usa CSR, você terá que lidar com o seguinte cenário: o método tem limitações dele para SEO, mas traz benefícios de performance para aplicações web e páginas interativas.
Portanto, muitas vezes a questão é mais complexa do que simplesmente trocar para renderização do lado do servidor.
Solução: muito diálogo com a sua equipe de desenvolvimento. Você precisará explicar os problemas para SEO e chegar a um “meio termo”, principalmente se não for possível trocar para renderização do lado do servidor.
Você deve defender que:
O site seja rastreável e indexável;
Esteja usando links rastreáveis (com tag <a>);
Conteúdo crítico deve estar disponível sem depender de renderização.
Quanto antes você identificar e comunicar a questão, melhor, pois ela escala e dá trabalho para resolver em aplicações complexas.
4. Os rastreadores não conseguiram carregar recursos para renderizar as páginas
Para renderizar uma página, o Google precisa ter acesso a uma série de recursos, como scripts e arquivos de mídia. Sem eles, a página fica incompleta.
Eles são ligeiramente diferentes de elementos como títulos ou meta tags, dos quais falamos anteriormente.
Você pode considerar os recursos de construção de uma URL como se fossem os tijolinhos que juntos formam a página.
Sem os tijolos, o Google deixa alguns buracos nas paredes.
Como descobrir o problema: use o teste de URL em tempo real do Google Search Console. Verifique se há algum erro visual na página por meio da captura de tela. Na aba “mais informações”, veja os recursos da página e as mensagens de console.
Nem tudo o que aparece aqui precisa de correção, mas por via das dúvidas, é melhor olhar junto com um desenvolvedor.
Possível causa: bloqueio no robots.txt
O robots.txt é um arquivo com as instruções sobre quais partes do seu site os robôs podem acessar.
Às vezes, scripts e imagens ficam dentro de um subdiretório ou subpasta que está bloqueado para rastreamento. Aí, fica ausente na hora da renderização, mas aparece para os visitantes.
Solução: basta revisar a configuração do seu artigo. Procure a localização dos arquivos CSS, JS e de imagem e certifique-se de que o Googlebot pode acessá-los.
Possível causa: problemas na interpretação do código
Em JavaScript, “parsing” é o processo de interpretar o código-fonte de uma página e convertê-lo em um formato que o navegador ou rastreador consiga entender e processar corretamente.
Alguns erros podem impedir esse processo, o que resulta em problemas de renderização.
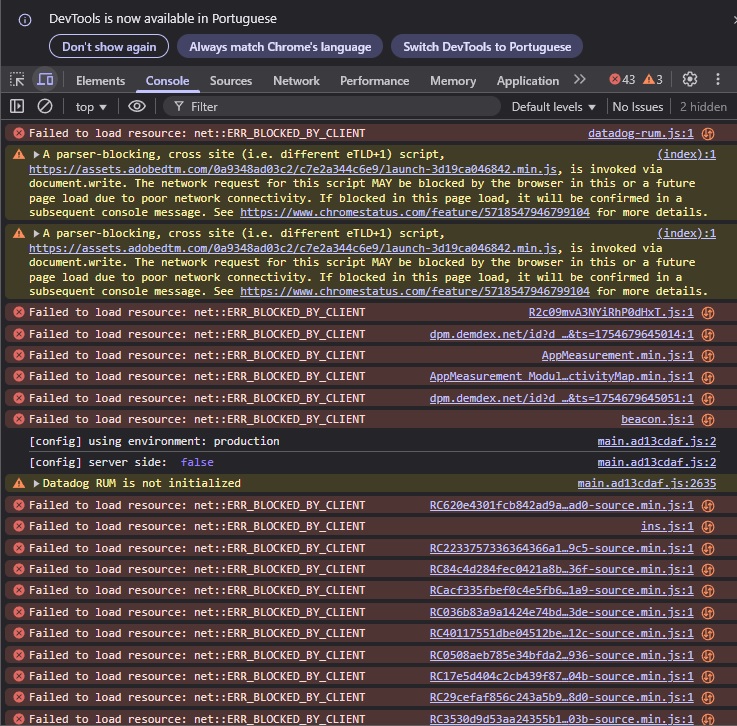
Você pode encontrar estes erros usando a inspeção de páginas no seu navegador e acessando a aba “console”. É muito comum encontrar diversos tipos de erro, como neste exemplo:
Bastante coisa, né? Mas muitos não interferem em SEO. O site de exemplo, inclusive, ranqueia muito bem.
Solução: diante desse cenário, o ideal é mostrar os erros para um desenvolvedor para entender quais de fato precisam de correção. Explique que você suspeita estar lidando com problemas de renderização e pergunte se algum dos erros está relacionado.
O cabeçalho <head> é um elemento HTML que agrupa uma série de tags importantes para rastreamento e indexação, como metadados e tag canonical.
Ela pode ser manipulada via JavaScript, o que pode gerar alguns tipos de problema, como a ausência de itens que o Google considera valiosos.
Como descobrir o problema: basta inspecionar o HTML pré e pós-renderização, caso você use CSR. Se o campo <head> estiver com as tags corretas antes de renderizar, está tudo certo.
Possível causa: tags alteradas após renderização
As tags presentes no cabeçalho <head> devem permanecer inalteradas antes e depois da renderização. Do contrário, o Google pode ficar confuso com sinais conflitantes sobre como indexar aquela URL.
Solução: tenha cautela ao permitir que o JS modifique dinamicamente os elementos do cabeçalho. Você deve sempre se certificar de que tags canonical e meta robots permanecem inalteradas na versão renderizada da página.
Possível causa: não há metadados
Metadados são tags que oferecem informações da página aos navegadores e mecanismos de busca, mas não são exibidos aos visitantes. Sem esses dados, os buscadores têm dificuldade em entender o conteúdo.
Se uma biblioteca JS for usada para criar e gerenciar o campo <head>, estes dados podem ficar completamente ausentes.
Solução: identifique qual biblioteca o seu site usa, verifique a documentação sobre inclusão de metadados e repasse as informações ao seu time de desenvolvimento.
6. JavaScript está gerando páginas indesejadas
Uma das principais vantagens do JavaScript é a capacidade de criar páginas dinamicamente. Mas, sem gerenciamento adequado, isto rapidamente se torna um problema.
Cada site tem um crawl budget, ou “cota de rastreamento”. É a quantidade de URLs que são rastreadas pelos robôs sempre que eles visitam o site.
Se o site tiver muitas URLs dinâmicas sendo rastreadas, o Google pode gastar todos os recursos nelas, sem passar pelas páginas realmente úteis e que devem ser indexadas.
Para sites pequenos, não faz tanta diferença, pois o buscador tem recursos para rastrear tudo. Mas, para sites grandes, milhões de URLs, é necessário controlar o que o Google rastreia e indexa.
Como identificar o problema: use o relatório de estatísticas de rastreamento do Search Console para identificar se o Google está conseguindo rastrear todas as URLs descobertas e se há algum erro.
Possível causa: Google está rastreando URLs internas
“URLs internas” são geradas dinamicamente, para que um serviço funcione corretamente.
Por exemplo, certos frameworks geram templates de páginas, que são hospedados em URLs com caminho /build antes de serem movidos para o seu destino final. Outros tipos de aplicações podem gerar URLs com um resumo de requisições de clientes.
Nada disso deve ser rastreado ou indexado, pois não oferece nenhum benefício direto aos visitantes.
Solução: exclua as URLs irrelevantes ou bloqueie-as no robots.txt. Para as que já tiverem sido indexadas, use a tag noindex para que elas deixem de aparecer.
Possível causa: paginação infinita
O JS pode gerar URLs “infinitas” de paginação, que podem ser detectadas e descobertas pelos rastreadores.
Por exemplo, o site só tem 10 páginas de conteúdo, mas existe uma URL que leva até a página 27.
Isso gera erros soft 404, que prejudica a visibilidade do site – acontece quando um conteúdo não existe, mas não mostra um status HTTP 404 ao visitante.
Solução: apresente o erro à sua equipe de desenvolvimento, para que eles criem uma lógica para a geração de URLs.
Possível causa: páginas não exibem status HTTP 404 adequado
É um erro comum em aplicativos de página única (SPA). Frequentemente, eles retornam código HTTP 200 (OK) mesmo se a URL não existir.
O resultado é que os visitantes enxergam uma coisa, e os rastreadores outra:
Os humanos recebem uma mensagem falando “conteúdo não encontrado”;
Os robôs recebem uma mensagem falando que o conteúdo exista, mesmo que não tenha nada na URL.
Isso gera confusão e pode prejudicar a visibilidade do site nos mecanismos de busca.
Solução: o seu site deve ter status 404 configurado corretamente para páginas que não existem.
Há diversas formas de fazer isso, que devem ser discutidas junto à sua equipe de desenvolvimento.
Duas opções com bom potencial para SEO são:
Configurar o servidor para que reconheça as URLs válidas e inválidas;
Criar um sitemap que inclua as URLs válidas dinamicamente e exiba o 404 para as que não estão lá.
Importante: muitos sites criam uma URL 404, como seusite.com/404 e redirecionam qualquer conteúdo que não existe para lá. Só que essa URL também exibe status 200! Ou seja, fica errado igual.
Melhores práticas de JavaScript para SEO
Para SEO, as boas práticas de JavaScript envolvem otimizar o carregamento e implementar os elementos de página de forma correta.
São pequenas ações que previnem os erros que você viu acima, aumentam a performance do site, facilitam a leitura para buscadores e melhoram a experiência de página para os seus visitantes.
Veja abaixo algumas dicas, extraídas de documentações do Google, comentários de engenheiros da big tech e da experiência de mercado da equipe da SEO Happy Hour.
1. Entregue elementos críticos via HTML sempre que possível
Prefira incluir via HTML todos os elementos que afetam a visibilidade da página. Entre eles:
Tag canônica: previne problemas de conteúdo duplicado;
Meta robots: tem as diretrizes para os robôs do Google;
Title e descrição: ajudam o Google a entender o conteúdo da página;
Dados estruturados: dão suporte a recursos extra do Google, como a exibição de preços de produtos na SERP;
Links: influenciam a descoberta de novas páginas;
Conteúdo da página: é o bloco principal de texto daquela URL.
Você pode inserir todos esses elementos via JS, mas isso aumenta o risco de erros de interpretação por parte do Google, o que gera falhas na indexação de páginas.
2. Revise os códigos de status HTTP
Códigos de status HTTP são as respostas que o Googlebot recebe sempre que indexa uma página.
Há vários tipos diferentes, que devem ser configurados de forma adequada. Em SEO, os mais relevantes são:
200: é o código padrão, indica que a requisição pode ser concluída;
404: conteúdo não encontrado;
401: bloqueado devido a solicitação não autorizada, acontece quando o servidor solicita credenciais ao Googlebot;
403: acesso proibido, acontece quando as credenciais informadas na hora da requisição foram consideradas inválidas;
301: conteúdo movido permanentemente, usado em redirecionamentos;
302: conteúdo movido temporariamente, usado em redirecionamentos que serão desfeitos futuramente.
Diferentes problemas podem acontecer se as respostas estiverem configuradas incorretamente.
Por exemplo, uma página que deveria apontar 404, mas retorna 200, gera um soft 404.
Já um redirect que deveria ser 302, mas é 301, transfere totalmente a autoridade para uma página temporária, que deixará de existir em breve.
Em longo prazo, isso significa trabalho jogado fora, já que outras ações de SEO perderão efetividade por causa dos problemas técnicos.
Em dezembro de 2025, o Google atualizou a documentação de JavaScript em SEO, explicando que páginas que não retornam o status 200 podem nem ser renderizadas. Portanto, tenha muita atenção ao gerenciar os códigos de resposta usando JS.
3. Atente-se para erros soft 404
O soft 404 é bastante comum em apps de página única, por isso merece atenção especial. Inclusive, já falamos dele lá em cima.
Segundo o Google, há duas soluções rápidas para o problema por meio de JS:
Redirecionando as URLs;
Inserindo a tag noindex nas páginas de erro.
4. Não esconda conteúdo atrás de interações
O Googlebot não executa nenhuma ação nas páginas, como clique. Também não aceita solicitações de permissão.
Sua página não deve depender disso para exibir o conteúdo. Os rastreadores devem ter uma visão geral sobre o conteúdo a partir apenas do HTML.
5. Tenha cuidado com redirecionamentos via JavaScript
Redirecionamentos JavaScript não são o ideal. Eles até funcionam, mas a preferência do Google é por redirects HTTP, que retornam status 301 ou 302.
A principal diferença é que os redirects via JS são sempre tratados como permanentes. Isso significa que eles transmitem toda a autoridade para a nova URL, o que nem sempre é o ideal.
No mais, os redirects HTTP acontecem do lado do servidor, o que os torna mais fáceis de processar por parte do Google.
Outra boa dica é evitar redirecionamentos sempre que necessário, principalmente as cadeias muito longas, com mais de 10 redirects.
Estas são duas dicas técnicas do engenheiro e porta-voz do Google Martin Splitt. Ambas têm o objetivo de deixar sites mais rápidos.
O code splitting “separa” os elementos de uma aplicação web, para que sejam carregados de forma independente e apenas quando necessário.
Já content hashing é uma técnica de cache. Por meio dela, os arquivos que não passaram por mudanças não precisam ser carregados a cada vez que o visitante acessa o site.
7. Use lazy load (com cautela)
Lazy load é usado para carregar elementos da página apenas quando eles são necessários. Ou seja, um conteúdo que está no final da página será carregado apenas quando a pessoa rolar até lá.
O code splitting, que apresentamos acima, é uma das técnicas usadas no lazy load, inclusive.
O principal benefício para SEO é a melhoria na performance do site. No entanto, ele deve ser usado com cautela, bloqueando apenas elementos não-críticos, como as imagens ilustrativas.
8. Use renderização do lado do servidor sempre que possível
A regra é clara: tudo o que puder ser entregue pronto pelo servidor deve ser. Isso inclui o conteúdo principal da página, a estrutura HTML e os metadados. Já os elementos que dependem de interação do usuário, como animações, menus expansíveis e demais elementos dinâmicos, podem ser renderizados no lado do cliente.
Fazendo isso, você tem o melhor dos dois mundos: as vantagens de performance para sites com conteúdo dinâmico e os benefícios de SEO quando isso não for necessário.
9. Teste o site com JavaScript desativado
Uma das melhores formas de identificar erros é acessar o site com JavaScript desativado.
Para fazer isso:
Acesse a ferramenta de inspeção do seu navegador (CTRL+SHIFT+C);
Pressione o botão de engrenagem;
Vá até os recursos de debug e desabilite o JavaScript;
Recarregue a página.
Você verá a versão “crua” dela, apenas com HTML e CSS. Assim, fica fácil identificar se tudo está aparecendo como deveria.
10. Revise a implementação do seu paywall
Em agosto de 2025, o Google adicionou diretrizes sobre paywall adicionado via JavaScript às páginas. A recomendação é disponibilizar o conteúdo completo apenas quando o status de inscrição for confirmado.
O que muitos sites fazem é apresentar o conteúdo completo na resposta do servidor, e ocultar parcialmente com código, para mostrar só o título ou primeiro parágrafo. Se for implementado assim, o visitante pode simplesmente desabilitar o JavaScript no navegador e acessar o conteúdo completo.
A alternativa recomendada pelo Google é fazer com que o servidor entregue o conteúdo completo apenas após validação da assinatura. Assim, visitantes não autenticados recebem uma versão limitada da página, enquanto assinantes têm acesso total.
O Google também recomenda adicionar dados estruturados de paywall às páginas. Assim, consegue identificar mais facilmente que se trata de um conteúdo legítimo protegido por assinaturas, e não uma técnica de cloaking.
O portal The Information é um bom exemplo de implementação. Perceba que mesmo sem o JavaScript, o conteúdo segue protegido:
11. Verifique o HTML renderizado no Search Console
Já apresentamos o método lá em cima, mas reforçamos: use a ferramenta de teste de URL em tempo real para entender como o Google está enxergando a sua página.
O painel mostra o código-fonte da página, uma versão renderizada e os possíveis erros de console ou de JavaScript encontrados pelo Googlebot.
12. Revise o uso de tag noindex
A tag noindex tem a função de impedir a indexação de páginas no Google. Quando ela está presente no HTML de uma página, o Google muitas vezes interrompe o processamento antes da renderização ou da execução de qualquer script.
Ou seja, não é seguro tentar alterar ou remover o noindex via JavaScript. Pode ser que o script até rode, mas o comportamento não é previsível e nem consistente. Por isso, o Google atualizou a sua documentação orientando a remover a tag do HTML de qualquer página que você quer indexar.
Na prática, isso afeta principalmente SPAs, páginas com testes A/B ou demais condições que gerenciam a tag do lado do cliente.
13. Gerencie a tag canonical
Outra atualização de documentação do Google detalha a implementação da canonical tag via JS. A recomendação principal é incluir no arquivo HTML sempre que possível. Caso não seja possível, é necessário ter uma série de cuidados especiais.
Isso acontece porque a tag é lida antes e depois da renderização. Ou seja, no início do rastreamento, o Googlebot identifica a tag no arquivo HTML. E quando a página é carregada, ele continua a enxergá-la. Sinais conflitantes podem gerar problemas de canonização.
Usar JS para manipular a tag abre brechas para gerar esse tipo de inconsistências, modificando a canonical após a renderização para algo diferente do arquivo HTML.
As boas práticas recomendadas pelo Google são as seguintes, dependendo da estrutura do seu site:
Inserir a tag apenas via HTML, para facilitar a leitura pré e pós renderização;
Se for necessário definir uma tag diferente via JS, então retire do HTML, para evitar sinais cruzados;
Em todas as instâncias, cada URL deve ter apenas uma tag canonical.
Diagnóstico profissional para problemas de JavaScript em SEO
JavaScript é sempre um assunto delicado, já que tem implicações em SEO e em desenvolvimento.
Para ter apoio no diagnóstico de problemas, implementação correta e diálogo com equipes de desenvolvedores, entre em contato conosco! Nosso time tem especialistas em SEO técnico, com experiência na auditoria de problemas de JavaScript para SEO.
Elyson Gums é redator na SEO Happy Hour. Trabalha com redação e produção de conteúdo para projetos de SEO e inbound marketing desde 2014, em segmentos B2C e B2B. É bacharel em Jornalismo (Univali/SC) e mestre em Comunicação Social (UFPR).





Comentários