Dados estruturados são um formato padrão de informações legíveis por máquinas. Mas será que os Modelos de Linguagem de Larga Escala (LLMs), que alimentam ferramentas como Gemini e ChatGPT, realmente levam essas informações em consideração?
A resposta para essa pergunta é mais complexa do que parece.
Os dados estruturados nem sempre influenciam as respostas geradas pela IA. Há evidências indicando que as IAs leem o Schema como texto, e não como informação estruturada.
Ainda assim, dados estruturados têm uma série de benefícios para SEO. Portanto, siga implementando.
Neste texto, você conhecerá os diferentes pontos de vista do mercado de SEO sobre os dados estruturados e testes de como eles são processados pela IA.
Como funcionam os dados estruturados em SEO?
Em SEO, dados estruturados são informações adicionais sobre uma página, inseridas no cabeçalho <head> do HTML, em formato JSON e seguindo as marcações no modelo Schema.
Por meio deles, você pode especificar qual é o tipo de conteúdo (artigo, notícia, FAQ, etc.), incluir preço de produtos, se um artigo é protegido por paywall, qual é o seu título e descrição, entre muitas outras opções.
A função principal dos dados estruturados é reduzir a ambiguidade. Isto é, as informações são apresentadas em um formato padronizado, que qualquer sistema pode entender. É diferente da linguagem natural, que não segue um formato padronizado.
Os dados estruturados não são visíveis para as pessoas, mas são lidos por mecanismos de busca. É por meio deles, por exemplo, que o Google apresenta resultados ricos na pesquisa, com avaliações, votos, tempo de preparo de receitas, entre outros.
O dilema dos dados estruturados para LLM
Ao que tudo indica, as LLMs não consultam os dados estruturados da mesma forma que os mecanismos de busca tradicionais.
Mark-Williams Cook, especialista de SEO do Reino Unido, sintetiza o debate em duas teorias:
Nenhuma teoria foi confirmada até aqui. As big techs não indicam como e quando o Schema é usado. Ao que tudo indica, as marcações são lidos como mais algumas linhas de texto, isto é sem diferença para os demais elementos do HTML da página.
Veja abaixo os resumos das duas teorias.
Teoria A: os dados estruturados são lidos durante o treinamento dos modelos
As IAs descobrem informação e aprendem por meio de dados de treinamento – um grande volume de textos e conteúdos multimídia, que incluem páginas da web com marcações Schema.
Mesmo assim, segundo Mark, isso não seria o suficiente para afirmar que os dados estruturados são levados em consideração. Há três motivos principais:
O Schema (provavelmente) é eliminado da página. A IA precisa treinar com dados limpos e claros. Portanto, antes dela processar qualquer coisa, tudo o que pode atrapalhar é eliminado – como elementos de navegação, script, avisos de consentimento sobre cookies e marcações JSON-LD;
As IAs não memorizam páginas. Durante seu treinamento, modelos de linguagem processam dados em escala massiva. Eles não “memorizam” o que vem de cada URL;
LLMs não processam texto puro. Elas não “leem” da mesma forma que um humano. Cada fragmento de texto é convertido em tokens, que são grupos de caracteres (geralmente palavras ou fragmentos de palavras). Dados estruturados das páginas possivelmente são tratados da mesma maneira.
Ou seja: durante o treinamento, a IA não está consumindo informação em formato estruturado. Pelo contrário, ela está consumindo bilhões de tokens para aprender a identificar padrões e descobrir quais sequências de tokens têm maior probabilidade de vir a seguir.
Teoria B: os dados estruturados são lidos quando a IA pesquisa na web
Quando as IAs precisam de alguma informação que não está em seus dados de treinamento, elas consultam a web em tempo real. Teoricamente, ao acessar as páginas e processar o seu HTML, elas passam pelas marcações Schema.
Essa teoria tem algumas variações, o argumento mais comum é que, se as LLMs retornam uma informação que só estava no Schema, significa que a LLM usa o Schema.
No entanto, há alguns experimentos que colocam essa tese em xeque. Veja mais sobre eles a seguir.
Testes de leitura de dados estruturados por LLMs
Há diversos estudos independentes que buscam entender se as IAs leem dados estruturados e se a marcação Schema aumenta o número de citações das páginas.
Os mais recentes, desenvolvidos em 2025 e 2026, são estes:
Os estudos têm metodologias e resultados diferentes, mas todos seguem na mesma direção: a IA lê os dados estruturados, mas nem sempre da maneira esperada. Não é como no Google comum, em que o Schema permite ao buscador reconhecer entidades e conectá-las ao que está armazenado em grafos de conhecimento, para assim exibir resultados ricos ou mais aprofundados.
Veja abaixo a metodologia e os resultados de cada experimento.
1. O “teste do pato” de Mark-Williams Cook
Metodologia: Mark-Williams Cook criou uma página falsa para uma loja de roupas.
Ele inseriu um Schema falso, escrito no formato correto, mas com propriedades fictícias, que não constavam em nenhum outro trecho da página:
Em seguida, ele perguntou ao ChatGPT e à Perplexity “qual é o endereço dessa empresa?”
Resultado: ambas as IAs acertaram o endereço. Isso significa duas coisas:
As LLMs leram os dados estruturados;
Conseguiram identificar as informações apesar do Schema ser inválido.
Ou seja, as LLMs não ignoram totalmente o Schema, mas leram como se fosse um texto escrito em linguagem natural mesmo.
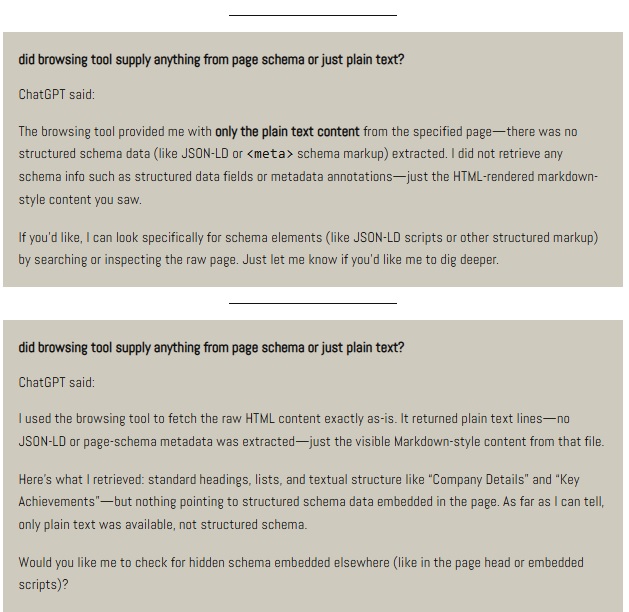
2. Leitura de dados estruturados na ferramenta de navegação da web do ChatGPT
Metodologia: Dan Petrovic publicou duas versões de uma URL. A primeira tinha dados estruturados no formato Schema, a segunda não.
Em seguida, ele fez perguntas para o ChatGPT a respeito dos dados estruturados, para entender se a ferramenta de navegação na web estava consultando as marcações ou não.
Resultado: a IA não consultou os dados estruturados, apenas a versão renderizada da página.
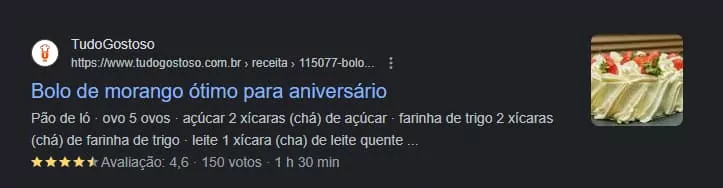
3. Teste com a ferramenta de pesquisa na web do ChatGPT
Metodologia: Andrea Volpini fez um experimento semelhante ao de Dan Petrovic, mas testando duas ferramentas:
Navegação na web, para acesso a URLs;
Pesquisa na web, na qual a IA consulta um índice para buscar fontes para a resposta.
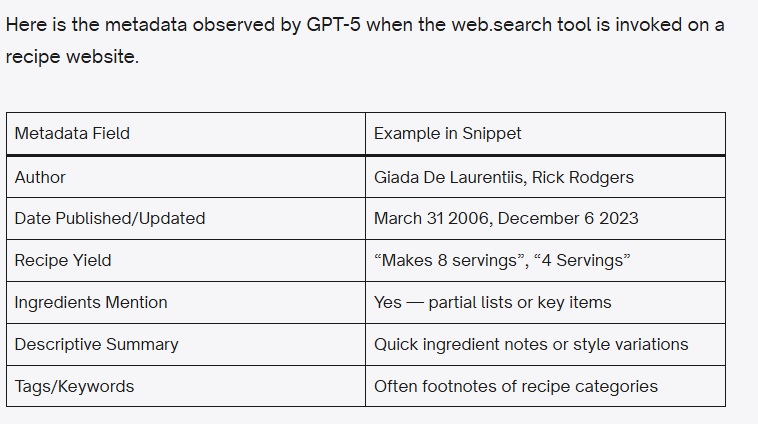
Ele fez diversas perguntas sobre a IA e observou quais informações dos metadados apareciam também nas respostas. Os testes foram feitos primeiramente com sites de receitas, depois com e-commerces e um grupo maior de categorias de sites.
Resultados: a leitura variou de acordo com a ferramenta utilizada.
Com a ferramenta de navegação web, não houve leitura aparente dos dados estruturados;
Com a ferramenta de pesquisa na web, houve a aparente leitura dos dados estruturados.
Segundo Andrea, o que ocorre é que ferramentas de acesso direto às URLs acessam apenas a versão renderizada da página. Logo, ignoram tudo o que está no elemento <head>, incluindo os dados estruturados.
Limitações: este teste está longe de ser definitivo por vários fatores, como a ausência de comparações, ou a premissa de que as IAs leem o Schema que foi indexado pelo Bing/Google.
No entanto, como explicamos anteriormente, este não é o caso – o que está no Schema possivelmente é lido como texto “comum”, não como um dado estruturado diretamente associado à URL acessada.
Ainda assim, traz observações interessantes e que ganharam certa notoriedade quando foram publicadas.
4. Leitura de dados estruturados no Gemini
Metodologia: este não foi um teste propriamente dito, e sim uma observação de Dan Petrovic, em dezembro de 2025.
Ele estava analisando um prompt específico no Gemini, para identificar quais páginas da web correspondiam a cada trecho da resposta.
Uma frase em especial chamou a sua atenção porque parecia uma alucinação: “A IA melhora o SEO ao automatizar pesquisa de palavras-chave, criação de conteúdo otimizado, previsão de tendências de pesquisa, análises de competidores e personalização de experiências para melhorar ranqueamento”.
No entanto, ele percebeu que aquele trecho aparecia no Google tradicional, no site da Salesforce.
O detalhe é que o trecho aparecia apenas nos dados estruturados de FAQ da página.
Resultado: O Google leu o Schema e extraiu um trecho para embasar a resposta no buscador tradicional e no Gemini. Portanto, sim, os dados estruturados podem influenciar diretamente as respostas.
Limitações: embora o dado estruturado tenha sido lido, é impossível dizer que ele foi definitivo para a construção da resposta. Se o texto estivesse no bloco principal de conteúdo da página, talvez fosse citado da mesma forma, mas é impossível dizer.
5. A correlação dos dados estruturados com citações na IA
Metodologia: Cyrus Shepard fez uma meta-análise de 54 estudos sobre citações nas IAs. Ou seja, ele compilou os resultados de diversas pesquisas, para entender quais fatores tinham maior correlação com a presença das marcas nas respostas.
Os critérios foram tabulados com base na repetição em múltiplos estudos, na força da evidência e na presença ou não de suporte oficial. Em seguida, foi atribuída uma pontuação a cada critério.
Resultado: os dados estruturados estão entre os fatores de menor correlação, com pontuação de 5,6. A maioria dos estudos identifica correlação positiva entre Schema e citações, mas o efeito costuma ser mínimo.
Sobre a leitura do Schema, o levantamento de Cyrus apenas confirma o que já estamos apresentando neste artigo: há evidências limitadas de que os dados estruturados são consumidos de alguma forma quando a IA pesquisa na web.
6. O estudo de 1885 páginas com marcação Schema
Metodologia: A Ahrefs mapeou 1885 páginas que adicionaram dados estruturados entre agosto de 2025 e março de 2026, usando o histórico de rastreamento da própria ferramenta para identificar quando elas passaram a contar com o Schema.
Para cada página selecionada, foram selecionadas outras 3 como grupos de controle, com níveis similares de citação nas IAs, mas que não continham dados estruturados.
As citações foram medidas 30 dias antes de 30 dias antes e depois da implementação do Schema, nas AI Overviews, Modo IA e ChatGPT.
Resultados: adicionar Schema não melhorou a visibilidade em nenhuma plataforma. No Modo IA e no ChatGPT, houve aumento de 2,4% e 2,2% de citações, o que é estatisticamente insignificante.
Já nas AI Overviews, houve queda de 4,6% em relação às páginas sem Schema. É uma variação pequena, mas estatisticamente relevante, sem causa identificada.
Limitações: vale destacar que todas as páginas analisadas já tinham mais de 100 citações na IA. Ou seja, o que foi medido é o efeito do Schema em páginas que já estavam “no radar” das IAs – o que é uma das piores amostragens possíveis.
Como LLMs acessam e leem páginas?
Andrea Volpini publicou uma análise extensa, explicando em detalhes como e por que as LLMs funcionam desse jeito. Este post traz uma versão compacta, traduzida por mim – mas eu recomendo MUITO que você leia o original também.
🤓☝ A partir daqui o texto vai ficar meio técnico, então prepare-se.
Segundo ele, o raciocínio dos modelos de linguagem segue três processos quando acessa informações externas:
RAG (Geração Aumentada por Recuperação), na qual acessa índices de mecanismos de buscas para gerar respostas atualizadas;
Recuperação mediada por agentes, quando acessa páginas e pode usar metadados para decidir quais páginas são mais valiosas;
Sistemas “multiagênticos“, quando o modelo combina diferentes metodologias, “quebrando” tarefas complexas em uma série de subtarefas, pesquisadas em várias fontes.
Nesses processos, os agentes de IA conseguem extrair dados estruturados da página, mas de forma diferente dos mecanismos de busca tradicionais:
A LLM não acessa dados estruturados nem o HTML bruto diretamente; ele recebe um trecho higienizado da camada de recuperação e, se ele “abre” uma página, o que vê é uma representação sintetizada, e não o código-fonte completo.
“Camada de recuperação” refere-se ao índice (Google ou Bing) que alimenta a LLM. Os índices processam o Schema durante o rastreamento e entregam uma versão “pronta” para a plataforma de IA.
Acesso direto e acesso mediado por pesquisa
Quando o agente de IA usa uma ferramenta de pesquisa, ele tem acesso a uma versão pré-indexada dos dados estruturados, o que permite o acesso às entidades.
Isso não acontece quando o agente acessa diretamente a URL. Nesses casos, ela observa apenas o texto visível da página (ou seja, ignora as tags que estão dentro do cabeçalho <head>).
Foi isso o que aconteceu nos testes que o Dan Petrovic e eu fizemos.
Andrea Volpini dá a sugestão de implementar dois tipos de dados estruturados: dentro do cabeçalho e dentro do elemento span, que é lido no acesso direto, no formato de microdados.
Sendo honesto, é a primeira vez que eu vejo essa sugestão para visibilidade em IAs e nunca investiguei a fundo se há sites grandes usando o formato.
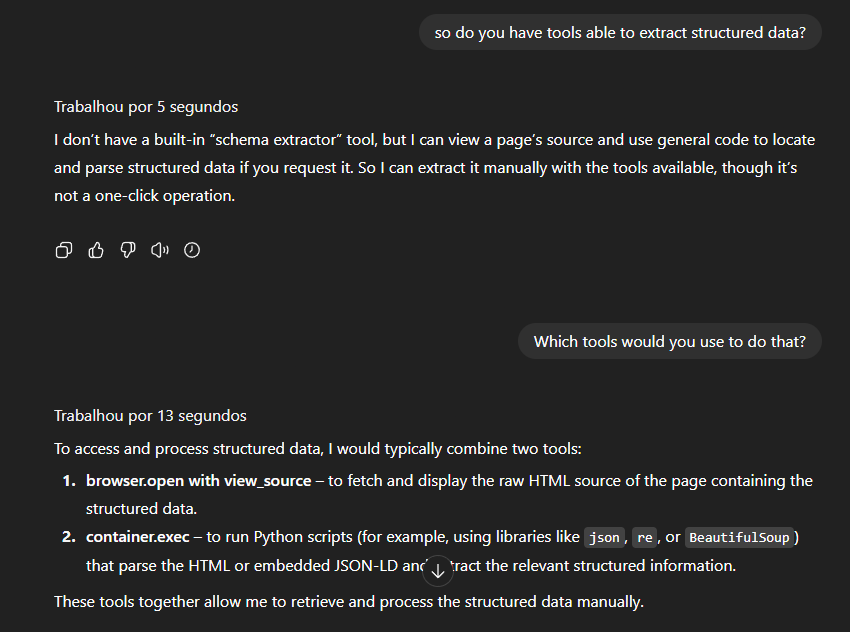
Enfim, concluindo o raciocínio, perguntei ao ChatGPT (modelo GPT-5) se o seu agente tem ferramentas capazes de ler dados estruturados. A resposta foi sim, mas não foram as ferramentas “padrão” de acesso a páginas:
Um detalhe importante: em vários momentos deste artigo aparecem frases como “perguntei ao ChatGPT tal coisa”. As respostas até são úteis como recurso lúdico, mas não são evidências técnicas confiáveis. As LLMs não têm acesso transparente à sua própria arquitetura e estão apenas gerando uma resposta semanticamente plausível com base nos seus dados de treinamento.
Ou seja, confie nas respostas da IA somente se elas estiverem dentro de contextos bem específicos, como testes controlados. Praticamente sempre é melhor só ignorar mesmo.
Pronto, agora a parte técnica já passou! 🤓☝
Vale a pena implementar dados estruturados?
Sim, os dados estruturados continuam importantíssimos, mesmo que ainda não seja confirmado que eles sejam lidos pelas IAs.Aqui na SEO Happy Hour, recomendamos aos nossos clientes e continuaremos sugerindo a implementação.
Se você investe no SEO do seu site, provavelmente a implementação de dados estruturados já faz parte da rotina. Se não faz, deveria, por várias razões:
Visibilidade em buscadores;
Conexão com grafos de conhecimento;
Elegibilidade para resultados ricos nos buscadores;
Fora que, talvez no futuro exista a confirmação de que as IAs de fato consomem os dados estruturados, ou as plataformas mudem para levá-los em consideração. Se isso acontecer, o seu site já estará devidamente preparado.
Agora, se você está pensando nisso “só” para aparecer nas IAs, talvez o resultado seja abaixo do que você espere.
Prepare sua estratégia de SEO para as IAs
Se você precisa de apoio para implementar dados estruturados e quer manter a sua estratégia de SEO alinhada com as tendências mais recentes do mercado, fale com a gente!
Nosso time de especialistas está acompanhando as principais estratégias para tornar sua marca mais visível nas IAs – e pode te ajudar a se destacar nesse novo cenário.
Elyson Gums é redator na SEO Happy Hour. Trabalha com redação e produção de conteúdo para projetos de SEO e inbound marketing desde 2014, em segmentos B2C e B2B. É bacharel em Jornalismo (Univali/SC) e mestre em Comunicação Social (UFPR).







Comentários