Dados estruturados são um formato padrão de informações legíveis por máquinas. Mas os Modelos de Linguagem de Larga Escala (LLMs), que alimentam ferramentas como Gemini e ChatGPT, realmente levam essas informações em consideração?
Como você já está acostumado em SEO, a resposta é: depende.
Dados estruturados são importantes para páginas, mas nem sempre influenciam nas respostas geradas pelas IAs. Logo, você deve continuar implementando, mas vale a pena ver os detalhes de como eles são processados pelas novas plataformas de IA.
Como funcionam os dados estruturados em SEO?
Se você clicou neste texto, provavelmente já conhece os dados estruturados, mas aqui vai uma explicação rápida para quem caiu aqui de paraquedas.
Basicamente, dados estruturados oferecem informações adicionais sobre uma página. São tags inseridas dentro do cabeçalho <head> de uma página.
Por meio deles, você pode especificar qual é o tipo de conteúdo (artigo, notícia, FAQ), indicar o preço de produtos, informações sobre a sua empresa, se um artigo faz parte de um paywall, entre muitas outras opções.
Essas marcações não aparecem para os visitantes, mas os mecanismos de busca leem para entender mais sobre uma página. O Google, inclusive, usa os dados para alimentar uma série de snippets na pesquisa, como os resultados ricos.
O dilema dos dados estruturados para LLM
Quando as LLMs foram lançadas, imaginava-se que elas consultavam os dados estruturados da mesma forma que os mecanismos de busca tradicionais.
Inclusive, vários tutoriais de “otimização para IA” disponíveis na internet orientam a implementar as marcações.
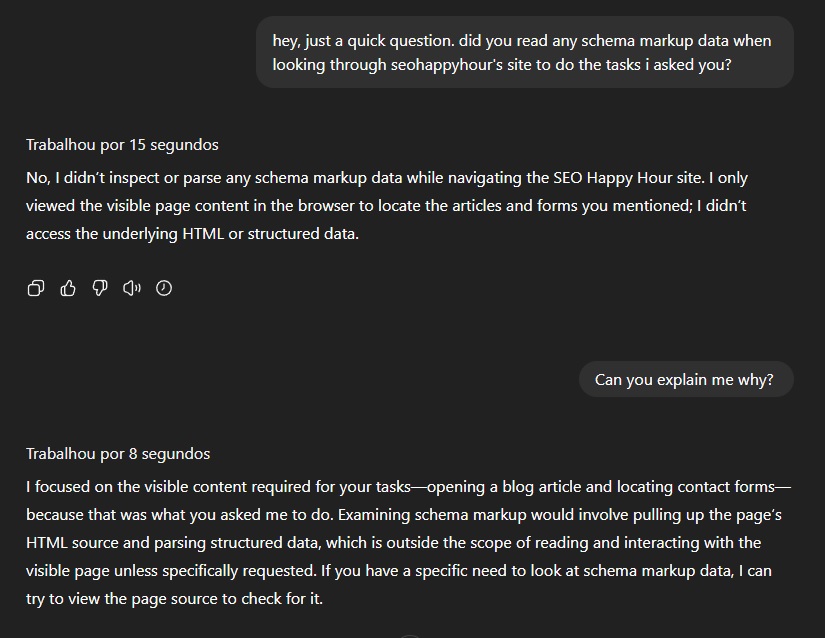
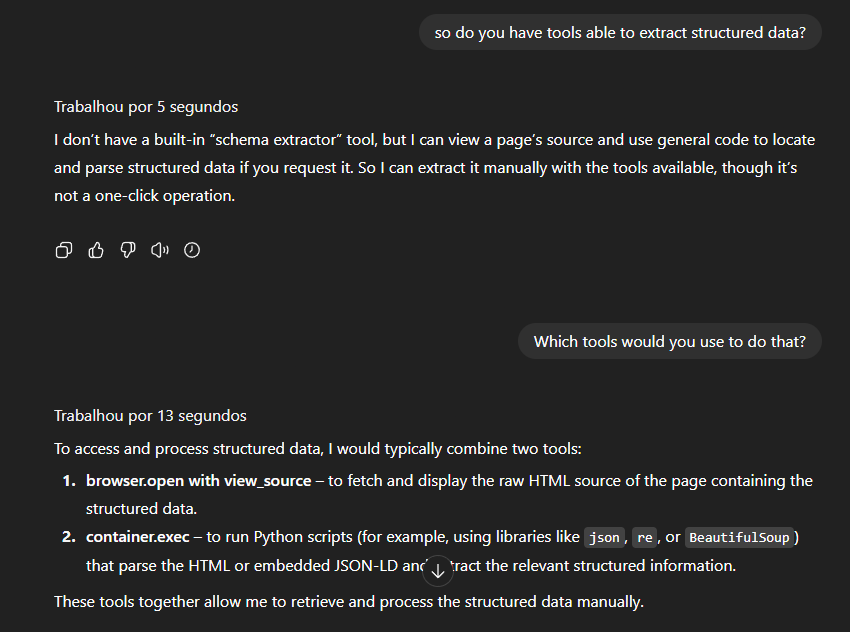
Comecei a ficar com dúvida sobre como funcionava de verdade enquanto eu fazia alguns testes com o agente de IA do ChatGPT.
Eu perguntei se ele estava consultando os dados estruturados da página que estava navegando e ele disse que não. Abaixo, está a conversa com o Chat. Está em inglês, mas ele disse que lê a marcação apenas se isso for essencial para realizar uma tarefa. Como não era, ignorou completamente.
Fui buscar mais informações e descobri que essa dúvida não era só minha. Encontrei no LinkedIn alguns testes e discussões sobre o assunto, que apresento aqui embaixo.
Testes de leitura de dados estruturados por LLM
Até aqui, a maioria dos experimentos são feitos manualmente, sem muita escala. A partir deles, é possível ter algumas pistas de como ChatGPT e Google lidam com as marcações em Schema ao gerar respostas.
Veja abaixo alguns testes realizados em 2025.
Teste de leitura de dados estruturados com a ferramenta de navegação do ChatGPT
Ele publicou duas versões diferentes de uma página, uma com dados estruturados e outra sem.
Depois, fez algumas perguntas para o ChatGPT, para entender se a ferramenta de navegação na web consultava dados estruturados ou não.
A resposta: não estava.
Teste com a ferramenta de pesquisa na web do ChatGPT
Andrea Volpini, da plataforma WordLift, fez testes parecidos, mas com diferentes ferramentas de agentes de IA do ChatGPT e Gemini.
A conclusão dele é que a leitura dos dados varia de acordo com a ferramenta usada:
Nas ferramentas de acesso direto à página, como a de navegação, não há leitura;
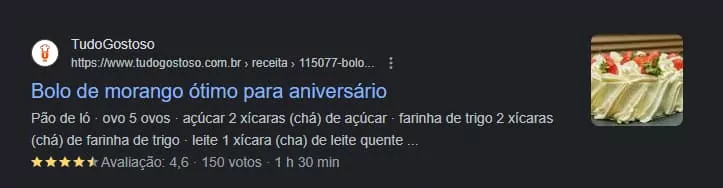
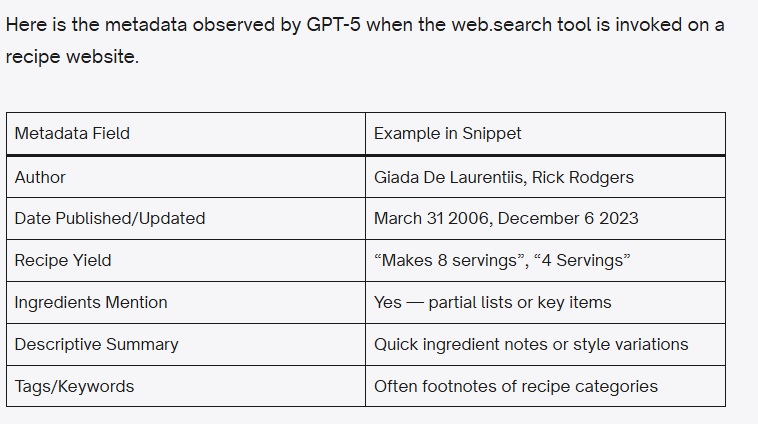
Na ferramenta de pesquisa na web, os dados estruturados são, sim, usados na geração de respostas.
Ele chegou a essa conclusão fazendo alguns testes com páginas de receitas e observando as menções a um dos seus clientes de e-commerce. Depois, fez algumas análises com tipos diferentes de conteúdo.
Teste de leitura de dados estruturados no Google
Em dezembro de 2025, Dan Petrovic fez um novo teste, desta vez para entender se o Gemini considera o Schema para gerar respostas.
A resposta: sim, os dados estruturados podem influenciar diretamente as respostas.
Ele chegou a essa conclusão enquanto analisava trechos de resposta do Gemini para um prompt específico. Seu objetivo era identificar quais páginas da web foram citadas em cada trecho do texto.
Uma frase em especial chamou a sua atenção porque parecia uma alucinação: “A IA melhora o SEO ao automatizar pesquisa de palavras-chave, criação de conteúdo otimizado, previsão de tendências de pesquisa, análises de competidores e personalização de experiências para melhorar ranqueamento”.
No entanto, ele percebeu que aquele trecho aparecia no Google tradicional, pois estava presente no site da Salesforce.
Ao acessar a página, ele percebeu que aquele trecho não aparecia na página, mas estava nos dados estruturados. Portanto, o Google leu o Schema daquela URL. No caso, extraiu um trecho da marcação de FAQ, velha conhecida de quem faz SEO.
Talvez se o texto estivesse no FAQ da página, seria citado mesmo sem marcação no Schema. É difícil dizer e possivelmente veremos mais testes nesse estilo em 2026.
Como LLMs acessam e leem páginas?
Andrea Volpini publicou uma análise extensa, explicando em detalhes como e por que as LLMs funcionam desse jeito. Este post traz uma versão compacta, traduzida por mim – mas eu recomendo MUITO que você leia o original também.
🤓☝ A partir daqui o texto vai ficar meio técnico, então prepare-se.
Segundo ele, o raciocínio dos modelos de linguagem segue três processos quando acessa informações externas:
RAG (Geração Aumentada por Recuperação), na qual acessa índices de mecanismos de buscas para gerar respostas atualizadas;
Recuperação mediada por agentes, quando acessa páginas e pode usar metadados para decidir quais páginas são mais valiosas;
Sistemas “multiagênticos“, quando o modelo combina diferentes metodologias, “quebrando” tarefas complexas em uma série de subtarefas, pesquisadas em várias fontes.
Nesses processos, os agentes de IA conseguem extrair dados estruturados da página, mas de forma diferente dos mecanismos de busca tradicionais:
A LLM não acessa dados estruturados nem o HTML bruto diretamente; ele recebe um trecho higienizado da camada de recuperação e, se ele “abre” uma página, o que vê é uma representação sintetizada, e não o código-fonte completo.
“Camada de recuperação” refere-se ao índice (Google ou Bing) que alimenta a LLM. Os índices processam o Schema durante o rastreamento e entregam uma versão “pronta” para a plataforma de IA.
Acesso direto e acesso mediado por pesquisa
Quando o agente de IA usa uma ferramenta de pesquisa, ele tem acesso a uma versão pré-indexada dos dados estruturados, o que permite o acesso às entidades.
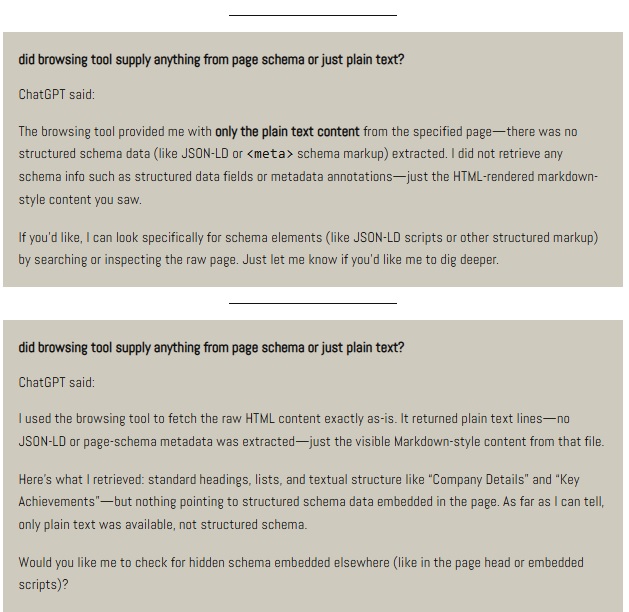
Isso não acontece quando o agente acessa diretamente a URL. Nesses casos, ela observa apenas o texto visível da página (ou seja, ignora as tags que estão dentro do cabeçalho <head>).
Foi isso o que aconteceu nos testes que o Dan Petrovic e eu fizemos.
Andrea Volpini dá a sugestão de implementar dois tipos de dados estruturados: dentro do cabeçalho e dentro do elemento span, que é lido no acesso direto, no formato de microdados.
Sendo honesto, é a primeira vez que eu vejo essa sugestão para visibilidade em IAs e nunca investiguei a fundo se há sites grandes usando o formato.
Enfim, concluindo o raciocínio, perguntei ao ChatGPT (modelo GPT-5) se o seu agente tem ferramentas capazes de ler dados estruturados. A resposta foi sim, mas não foram as ferramentas “padrão” de acesso a páginas:
Um detalhe importante: em vários momentos deste artigo aparecem frases como “perguntei ao ChatGPT tal coisa”. As respostas até são úteis como recurso lúdico, mas não são evidências técnicas confiáveis. As LLMs não têm acesso transparente à sua própria arquitetura e estão apenas gerando uma resposta semanticamente plausível com base nos seus dados de treinamento.
Ou seja, confie nas respostas da IA somente se elas estiverem dentro de contextos bem específicos, como testes controlados. Praticamente sempre é melhor só ignorar mesmo.
Pronto, agora a parte técnica já passou! 🤓☝
Vale a pena implementar dados estruturados?
Sim, os dados estruturados continuam importantíssimos.
Aqui na SEO Happy Hour, recomendamos aos nossos clientes e continuaremos fazendo isso.
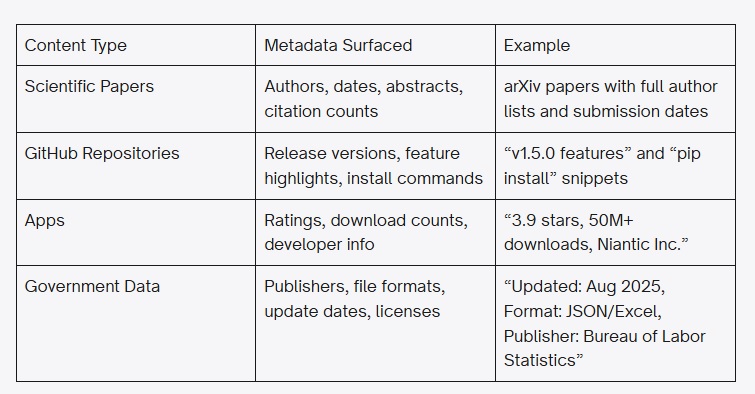
Fora dos benefícios já conhecidos para o Google, como a presença em snippets destacados, os dados estruturados ajudam as LLMs a entenderem a sua marca corretamente.
Quando você implementa os dados, oferece uma fonte extra de informação, o que facilita a representação da sua marca quando as suas páginas são acessadas.
Nas palavras de Andrea Volpini, os dados estruturados são críticos por duas razões:
Entidades em vez de palavras-chave: a IA recupera “coisas” (entidades com atributos), não “strings” (palavras-chave). O sucesso depende de fornecer dados legíveis por máquina que descrevam essas entidades de forma clara.
Dados estruturados como protocolo de grounding: o Schema.org em formato JSON-LD deixou de ser apenas um recurso para rich snippets do Google – agora é o principal protocolo para oferecer uma base factual e verificável para LLMs e agentes de IA.
Os benefícios dos dados estruturados para buscadores tradicionais também podem se refletir nas LLMs, principalmente se a teoria de que o ChatGPT usa dados do Google for verdadeira. Como o Google usa os dados estruturados para gerar snippets e o ChatGPT usa esses snippets, é possível que eles influenciem indiretamente a representação de marcas nas respostas do chatbot.
Prepare sua estratégia de SEO para as IAs
Se você precisa de apoio para implementar dados estruturados e quer manter a sua estratégia de SEO alinhada com as tendências mais recentes do mercado, fale com a gente!
Nosso time de especialistas está acompanhando as principais estratégias para tornar sua marca mais visível nas IAs – e pode te ajudar a se destacar nesse novo cenário.
Elyson Gums é redator na SEO Happy Hour. Trabalha com redação e produção de conteúdo para projetos de SEO e inbound marketing desde 2014, em segmentos B2C e B2B. É bacharel em Jornalismo (Univali/SC) e mestre em Comunicação Social (UFPR).




Comentários